
RLHF for Grammar Error Correction
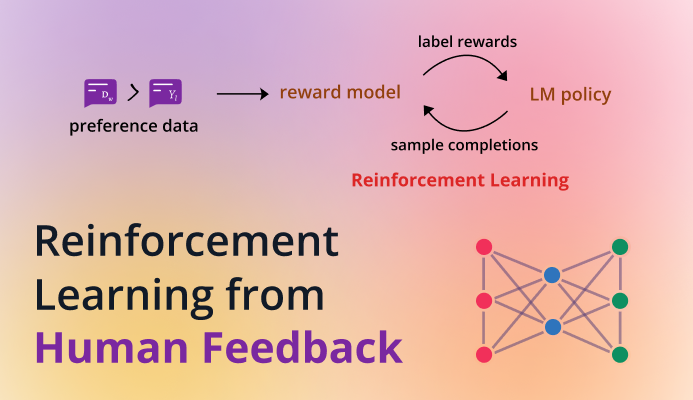
Introduction
At Trinka AI, we have built a Grammar Error Correction (GEC) model specifically designed to assist non-native speakers of English. Our model revises written language to make it accurate and fluent, particularly in academic contexts. In this blog, we highlight a key experiment: incorporation of Reinforcement Learning from Human Feedback into our workflow.
Our GEC model covers a broad range of writing errors and provides accurate text revisions. However, we understand that some clients require tailored solutions. For instance, a legal professional might need corrections and style suggestions that differ from what a medical researcher would require. While a phrase like “the patient exhibited no notable symptoms” is standard in medical research, the phrase “the transformed E. coli were reluctant to express the protein” might not be suitable.
Technical Background: Reinforcement Learning from Human Feedback
In the field of Natural Language Processing (NLP), Reinforcement Learning from Human Feedback (RLHF) has garnered significant attention following the emergence of ChatGPT [1]. RLHF was initially introduced around 2017, playing a crucial role in the development of InstructGPT [2]. However, with the surge in ChatGPT’s popularity, the spotlight turned definitively on RLHF.
RLHF is a fascinating methodology that incorporates human feedback directly into the training process of machine learning models. This approach enhances the model’s ability to process and respond in more human-like ways.
For a detailed understanding of RLHF, we will delve into an insightful paper on the subject [2]. Additionally, there are numerous blogs that extensively discuss this innovative NLP technique [3], [4], [5].
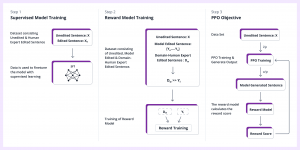
Figure 1 is derived from the InstructGPT paper [2]. It depicts the three-step process involved in the Reinforcement Learning from Human Feedback (RLHF) method.
Step 1: Supervised model training
- Fine-tuning a model on a single task or multiple tasks using a training dataset which comprises a prompt as an input and its desired output.
Step 2: Reward model training
- This is an important step of RLHF. The input prompt is shown to the user along with a variety of outputs from different configurations. The user then reorders these outputs, ranking them from the most to the least valid.
- This data is then provided to a reward model to train it. During training, the reward model is shown two suggestions at a time, and it is designed to assign a higher score to the best ranked suggestion.
- This generated data can also be called preferential data.
- Once trained, the reward model will give you a score that will tell how good that suggestion is.
- The loss function to train the reward model is given as follows [2]:
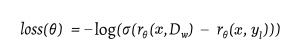
- In this context, “Dw” represents the correct suggestion, i.e., the one with a higher ranking, while “yl” denotes the suggestion with a lower ranking. The reward function, “rθ“, provides a scalar score based on the prompt and its corresponding suggestion.
- Subsequently, a log sigmoid function is applied to the loss function. This results in a lower score or assigns a low penalty if the reward for the higher-ranked suggestion is greater than the reward for the lower-ranked suggestion, and vice versa.
Step 3: Supervised model optimization with the reward model using PPO objective
- During this phase, a prompt is selected from the dataset and fed into the model, which then generates an output. The effectiveness of the output is assessed using the reward model, which calculates its reward score. This calculated reward is then used to update the model/policy using Proximal Policy Optimization (PPO).
- The objective of training the PPO policy is described in the same paper as follows [2]:
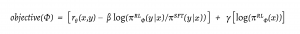
- When training the PPO objective, the “γ” parameter is set to zero. This approach involves the policy model computing a reward score for each prompt and its suggested response. KL divergence [6] is then applied on the policy model and the original model to ensure model stability, and it prevents excessive divergence.
Our Use Case
We developed a GEC model trained on millions of proprietary data points and capable of competitive accuracy and coverage. However, certain clients, particularly academic journals, require a solution tailored to their unique requirements and aligned with their specific style guidelines.
To this end, we applied the RLHF technique to a prominent scientific journal and observed that the model effectively move towards the content typically published in the journal.
We had already performed step 1, i.e., training a supervised model, as our existing GEC model was already in place. This left us to focus primarily on steps 2 and 3, i.e., training a reward model and fine-tuning the PPO objective.
To train the reward model, we had to prepare the training data. In our scenario, the “prompt” is essentially a sentence that requires editing. We have sentences edited by human experts that comply with the specific guidelines of the journal. We also have the GEC model outputs of the same sentences.
In this context, “x” represents the sentence that requires edits, “Dw” is the version edited by human experts, and “yl” is the output generated by our current GEC model. Our goal was to construct a reward model that assigned higher scores to sentences edited by humans and lower scores to those generated by the model. We did not include data points where the edits made by humans and the model were identical. Furthermore, we generated multiple suggestions, i.e. “yl” for the given “x” based upon different checkpoints and generation parameters.
We used Hugging Face’s Transformer Reinforcement Learning (TRL) library [7] to train the PPO objective. TRL is a full stack library that offers a complete suite of tools to train transformer language models using reinforcement learning. TRL applies the SFT and RM steps to the final optimization stage of PPO. We used the PPOTrainer class from the TRL library to train the PPO objective which considers the original policy, i.e., the GEC model and reward model that we trained using the above step.
NOTE: We tried optimizing the PPO objective with adaptive KL but the model started generating sub-optimal responses. Hence, we switched to static KL coefficient for optimization. It is crucial to note that setting the KL coefficient too low can cause the model to produce awkward responses.
Evaluation and Results
We evaluated the reward model by using our held-out dataset of 10,000 entries and observed noticeable enhancements across various metrics. The models were assessed using metrics like M2 Score [8] and BLEU [9]. With regard to the M2 score, we observed a significant increase of 2.9% in the F0.5 score. A similar trend was observed in BLEU scores too, the details of which are depicted in Figure 2.

It is evident that the journal-specific RLHF GEC model aligns more closely with the human experts’ revisions. We assume that enriching the training of the reward model with additional data will further narrow the gap between the model’s output and human-expert-level corrections.
Conclusion and Next Steps
Our team trained an RLHF model tailored to the specific needs of a prominent scientific journal publisher. This model, fine-tuned using our in-house GEC model, which is currently in use in our flagship writing app Trinka AI (www.trinka.ai) , demonstrated a solid 2.9% improvement in the F0.5 score. This outcome aligns closely with the quality of revisions made by human experts. We recognize that further significant improvements are possible by incorporating more specialized datasets, thus enhancing the model’s alignment with human-expert-level precision.
Training an effective RLHF model is not without its challenges. A key difficulty lies in simultaneously training two independent models: the reward model and the PPO. To streamline this complex process, we are now delving into Direct Preferential Optimization (DPO) [10] as a potential solution.
Looking ahead, we aim to expand the application of the RLHF technique to other publishers and journals. Our goal is to further analyze and understand the behavior of these models in different publishing contexts with an eye towards continuous refinement and adaptation.
If you would like to see the examples of the trained RLHF model or if you are a publisher or a company looking to enhance business communications/branding and would like to know how to create RLHF models that reflect your style and communication objectives, write to us at sales@trinka.ai.
References
[1] OpenAI, “Introducing ChatGPT,” OpenAI, Nov. 30, 2022. https://openai.com/blog/chatgpt
[2] L. Ouyang et al., “Training language models to follow instructions with human feedback,” Mar. 2022. Available: https://arxiv.org/pdf/2203.02155.pdf
[3] A. Thakur, “Understanding Reinforcement Learning from Human Feedback (RLHF): Part 1,” W&B, Nov. 02, 2022. https://wandb.ai/ayush-thakur/RLHF/reports/Understanding-Reinforcement-Learning-from-Human-Feedback-RLHF-Part-1–VmlldzoyODk5MTIx#learning-to-summarize-with-human-feedback (accessed Dec. 21, 2023).
[4] N. Lambert, “Illustrating Reinforcement Learning from Human Feedback (RLHF),” huggingface.co, Dec. 09, 2022. https://huggingface.co/blog/rlhf
[5] “RLHF (Reinforcement Learning From Human Feedback): Overview + Tutorial,” www.v7labs.com. https://www.v7labs.com/blog/rlhf-reinforcement-learning-from-human-feedback (accessed Dec. 21, 2023).
[6] Wikipedia Contributors, “Kullback–Leibler divergence,” Wikipedia, Apr. 16, 2019. https://en.wikipedia.org/wiki/Kullback%E2%80%93Leibler_divergence
[7] “TRL – Transformer Reinforcement Learning,” huggingface.co. https://huggingface.co/docs/trl/index (accessed Dec. 21, 2023).
[8] D. Dahlmeier and H. Ng, “Better Evaluation for Grammatical Error Correction,” 2012. Available: https://aclanthology.org/N12-1067.pdf
[9] K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “BLEU: a Method for Automatic Evaluation of Machine Translation,” Proceedings of the 40th Annual Meeting on Association for Computational Linguistics – ACL ’02, 2001, doi: https://doi.org/10.3115/1073083.1073135
[10] R. Rafailov, A. Sharma, E. Mitchell, S. Ermon, C. D. Manning, and C. Finn, “Direct Preference Optimization: Your Language Model is Secretly a Reward Model,” arXiv.org, May 29, 2023. https://arxiv.org/abs/2305.18290
Enhance Your Writing with Trinka’s Grammar Checker
Trinka’s Grammar Checker is designed to help writers produce clear, polished, and publication-ready content with ease. Whether you’re drafting academic papers, professional documents, or blog posts, Trinka ensures your writing is precise, consistent, and impactful, making it a trusted companion for anyone aiming to communicate effectively in English.

-
Go beyond grammar & spelling
Get holistic language improvements - Write with Trinka