Google NGram
viewer searches
This episode of the Trinka podcast explores Google's free tool, Google Books Ngram Viewer, a platform that allows users to search for frequency of usage of words and phrases in books.

Introduction
The speaker starts this video with the story of having received a document from his colleague. It had the following word in it: “good bye,” i.e. the words “good” and “bye” with a space in between. For a moment, our speaker was riddled with doubt- was this the correct way of writing this word?
Such doubts creep into all of our minds from time to time where we are not quite sure about the correct iteration of a word, and in such cases the first instinct is to do a web search, majorly on Google. However, are there any better ways to do it? That’s what this video explores.
Meet the Host

Google NGram: a free tool by Google
In this episode of the Trinka podcast, Dr. KK walks us through a free tool offered by Google- the Google Books NGram Viewer and some searches on that platform.
For example, to dispel the doubt about “goodbye” vs “good bye,” he used the Google NGram search which came up with an answer from a reputable source. The search showed a result from the website of Prof Paul Brians, Washington State University which proved that both “good bye” and “goodbye” are correct iterations, although it’s the latter which is more popularly used, as it has the advantage of recalling the words’s origin in phrases like “God be with ye”!
What are NGrams?
According to deepai.org, “An N-Gram is a connected string of N items from a sample of text or speech. The N-Gram could be comprised of large blocks of words, or smaller sets of syllables. N-Grams are used as the basis for functioning N-Gram models, which are instrumental in natural language processing as a way of predicting upcoming text or speech.”
Google Books NGram viewer interface
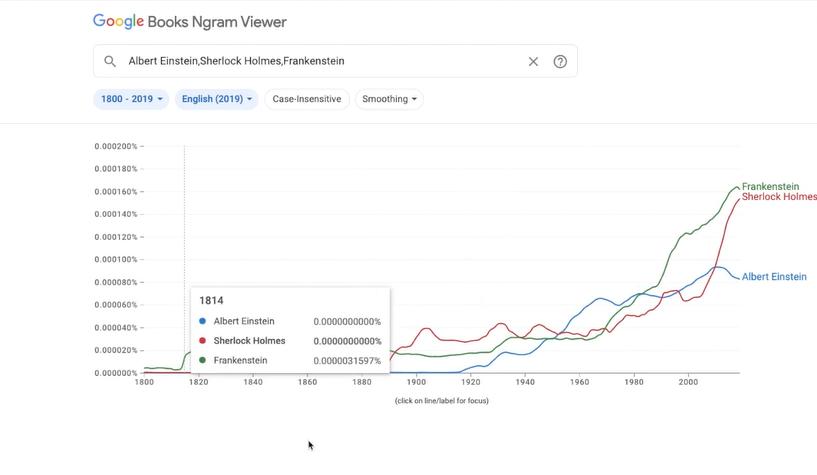
As you can see from the image below, the homepage shows a search with three names- Albert Einstein, Sherlock Holmes, and Frankenstein, followed by a graph representing the frequency of these names in the books. There are some criteria on the basis of which you can do these searches
Google NGram and the Frequency of Usage of Particular Styles
If you can see the graph above, the y axis is the percentage of occurrence of these names, and the x axis is the years. In the graphs, the lines tell you the frequency or how the trends are and you can see that it is currently adding the latest. The 2019 Frankenstein is most frequently mentioned, followed by Sherlock Holmes, followed not too closely by Albert Einstein. You can just basically hover over these graphs and see where the peaks and troughs are, for example, there was peak for the mention of Sherlock Holmes around 1904, compared to the early 90s When Frankenstein shot into being mentioned more frequently.
About the Trinka Podcast
This podcast is a continuation of Trinka AI's goal to improve academic writing and promote the sharing of scholarly knowledge. Upcoming episodes will provide language advice for non-native English speakers, as well as updates on language technology and research tools. Additionally, we will feature videos that explain NLP concepts like sentiment analysis, and interviews with experts from Trinka AI and other fields.
Don't miss our
latest episodes
Get notified when a new episode is released!
